Manugen AI - Agent Development Kit Hackathon with Google Cloud





Researchers today navigate an increasingly complex landscape: from securing funding and navigating ethical approvals to designing robust methodologies and managing ever-growing datasets, the path from hypothesis to discovery is fraught with logistical, technical, and interpersonal hurdles. Yet even once experiments conclude and results are compelling, a new challenge emerges—translating months, or sometimes years, of work into a concise, coherent, and publishable manuscript. Crafting such a paper demands mastery not only of scientific rigor but also of narrative flow, clarity of argument, and precise language, all under the pressure of journal deadlines and peer review. These dual demands often pull scientists in opposite directions: immersed in the nitty-gritty of data collection and analysis, they must then shift gears to adopt the wide-angle lens of storytelling, framing the big question, situating findings within a broader scholarly conversation, and articulating implications for future work. Moreover, time spent polishing figures, formatting references, and resolving reviewer comments is time diverted from deeper scientific inquiry—yet without this effort, the impact of the research remains unrealized, making writing not a mere afterthought but an integral and often underestimated component of the scientific endeavor.
A Real-World Test of Google-ADK

We saw the Devpost hackathon “Agent Development Kit Hackathon with Google Cloud” as an ideal proving ground for Google’s Agent Development Kit because it offered a fast-paced, collaborative setting in which to experiment with orchestrating specialized AI agents end-to-end. In a short amount of time, we could spin up retrieval, summarization, drafting, and revision agents, wire them together through Google ADK’s built-in state management, and immediately observe how small prompt tweaks or workflow adjustments affected overall output quality. The hackathon’s tight timeframe forced us to confront real-world integration and error-handling challenges—everything from passing context cleanly between agents to gracefully recovering from unexpected generation failures—while also giving us confidence that an agent-based architecture can dramatically streamline the scientific writing process.
What Inspired Us
From the outset, we were captivated by the promise of autonomous AI agents collaborating to tackle complex, multidisciplinary tasks. The Agent Development Kit Hackathon with Google Cloud challenged participants to “build autonomous multi-agent AI systems” capable of content creation, among other applications.

Recognizing that writing a rigorous scientific manuscript involves navigating vast literature, synthesizing nuanced insights, and maintaining a coherent narrative, we saw an opportunity to apply multi-agent orchestration to streamline and elevate the research-writing process. The hackathon’s emphasis on orchestrated agent interactions inspired us to ask: what if specialized agents—each expert in retrieval, summarization, drafting, and revision—could work in concert to produce a high-quality scientific paper?
What It Does
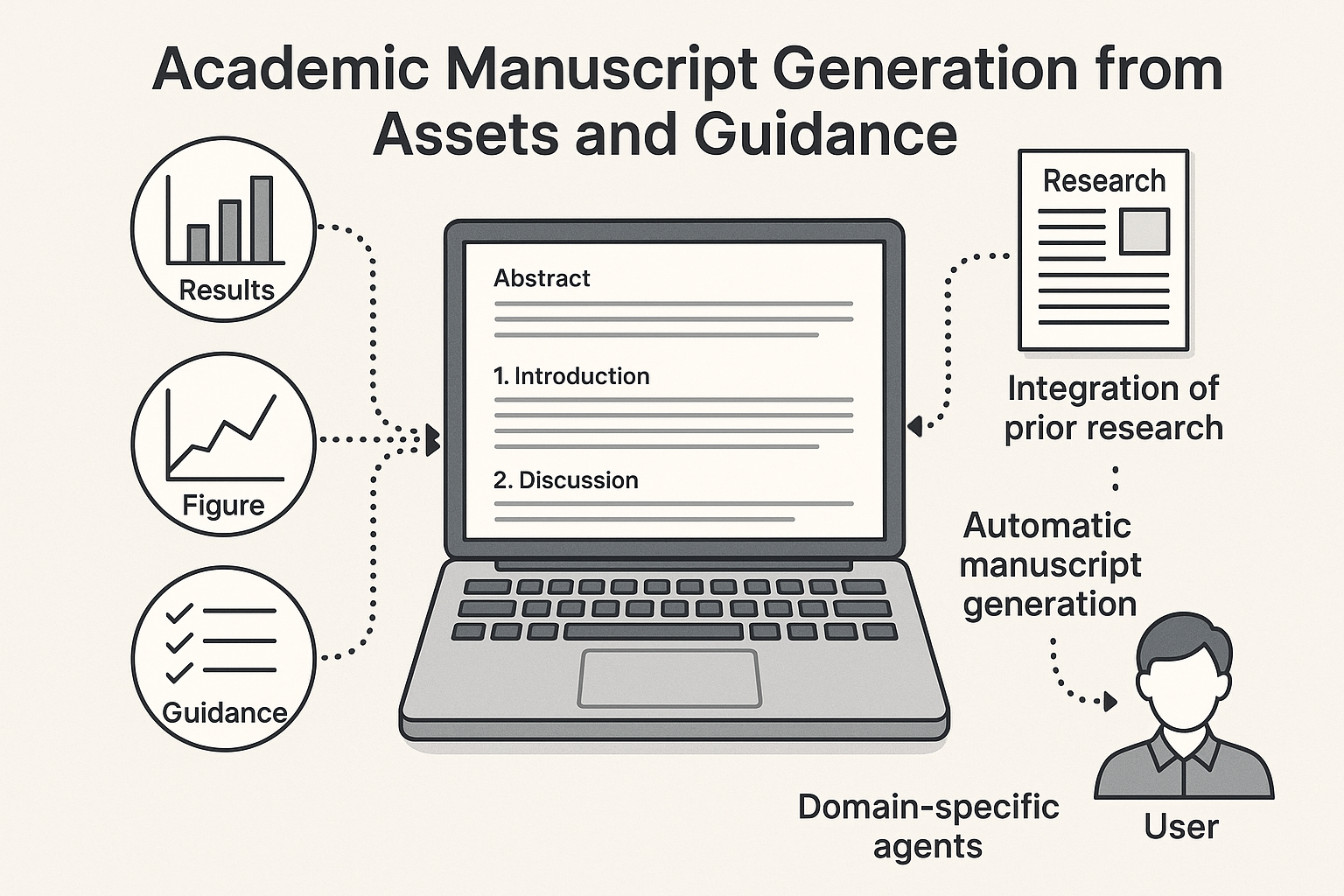
We built Manugen-AI, an agentic system that can take experimental results generated by humans, such as figures and rough descriptions of results, and generate a full, well-structured scientific manuscript.
We built a UI that allows the user to upload figures, enter Markdown with a bullet list of rough instructions for the system, and draft sections incrementally.
When uploading a figure, the system will use a specific agent that will interpret it by generating a title and description that the Results-section agent will use later to reference figures and explain results.
When the user enters a URL to a source code file, like a .py Python file, the Methods-section agent will use a tool to download the file, learn how the method works, and provide an explanation by drafting the Methods section.
The user can use Manugen-AI to go from results, figures, and rough instructions, to a fully drafted, and well-structured scientific manuscript draft in minutes, speeding up science communication significantly.
Check out our short demo video and GitHub repo!
How We Built It
-
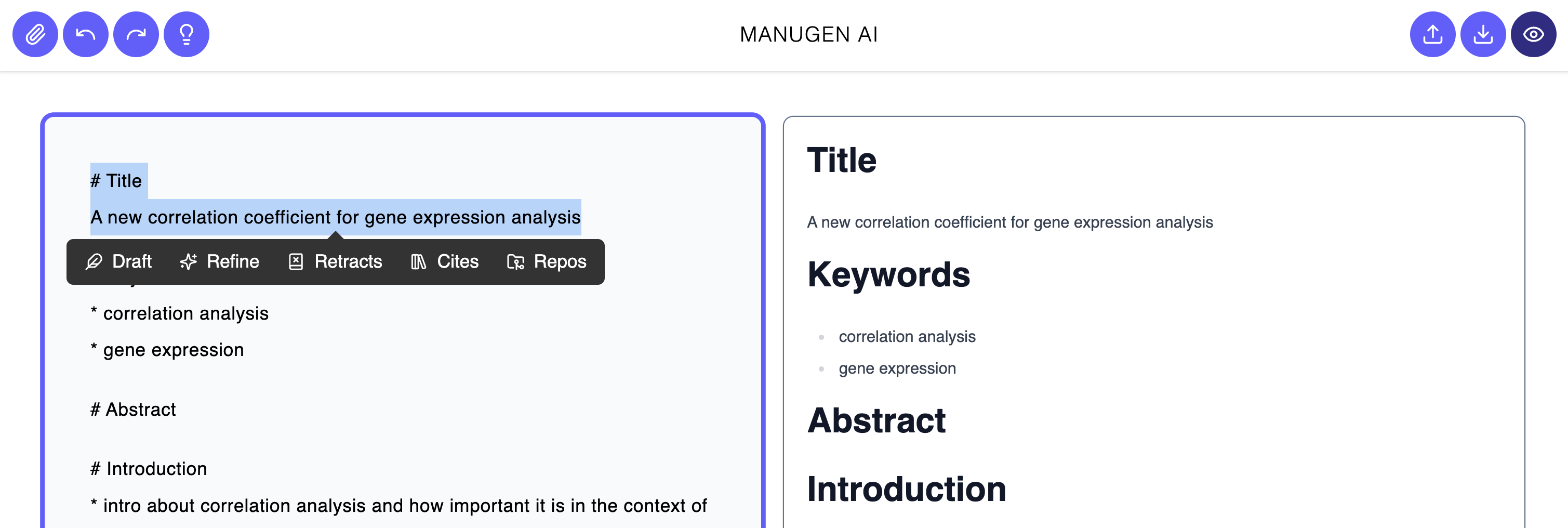
User Interface. We created a web interface which helps users write their paper content with the help of AI‐assistant actions. Under the hood, we used FastAPI to provide an API service layer to a Vue.js front‐end. This streamlined interface means that users can quickly get input on their work directly in a browser. It offers an intuitive writing environment that offers agentic input in the form of specific actions. Users can leverage one of many options, described in detail below. Once agents have taken actions on the content, users may analyze the results and make iterative improvements on the content.
-
Agent Roles & Pipeline:
We used the Python version of ADK to define each agent’s behavior and orchestrate the workflow, tapping into its built-in support for asynchronous execution and state management.
-
Coordinator Agent: A
CustomAgentthat orchestrates the entire manuscript workflow by interpreting the user request using clear rules implemented in Python, dispatching tasks to sub-agents (drafting, figures, citations, review, repo extraction), managing shared context and state, and collating each agent’s outputs into a unified draft.
Core Agents
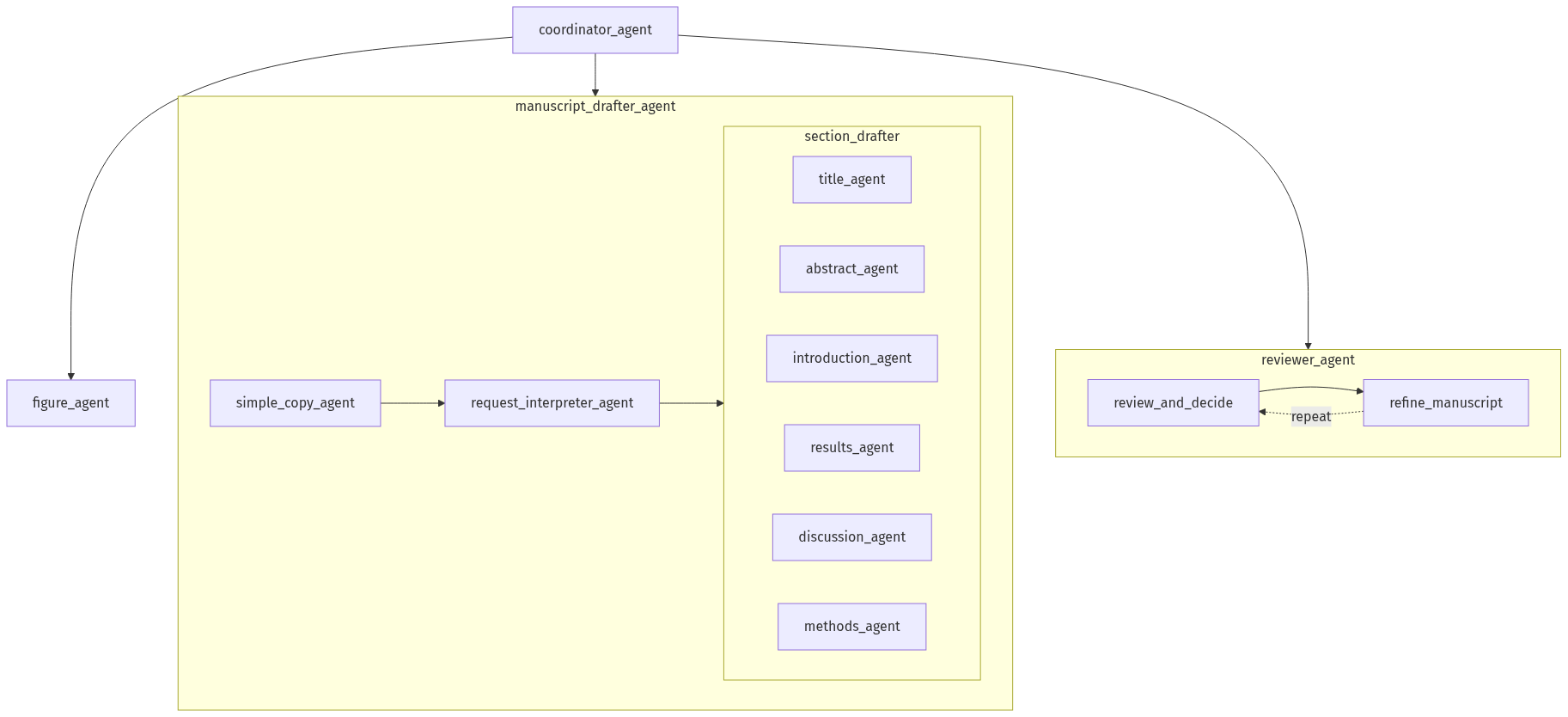
The following agents are invoked as core functionality by the coordinator agent.
-
Manuscript Drafter Agent: A
SequentialAgentthat runs the following agents sequentially: the “Request Interpreter Agent” (anLlmAgentthat tries to interpret which section the user wants to draft, or what the user is requesting to edit in an already drafted section) and the “Section Drafter Agent” that delegates to the section-specific agent for drafting either the Title, Abstract, Introduction, Results, Discussion, or Methods sections (all of them beingLlmAgents). All these agents share a state and access different section drafts that are relevant for them. The Results agent, for instance, has access to the current figures’ titles, descriptions, and numbers (e.g., “Figure 1,” “Figure 2”), all of them generated by the “Figures Agents” (LlmAgent). In our demo video, we show how the Results agent uses this information about figures to draft paragraphs explaining all their details. The Methods agent can detect URLs to external text files, such as Python files implementing a method, by using an external tool that retrieves the content; then, the agent interprets the source code and extracts relevant information about the computational approach to explain how it works automatically. Since each section of a scientific manuscript has a particular structure, these section-specific agents incorporate this knowledge on how to properly write a section. For example, the Introduction agent’s prompt has instructions to highlight the “gap that exists in current knowledge or methods and why it is important”, which is done by “a set of progressively more specific paragraphs that culminate in a clear exposition of what is lacking in the literature, followed by a paragraph summarizing what the paper does to fill that gap.” - Figure Agent: Responsible for explaining figures uploaded by the user, identifying different types of plots (like an UpSet plot), numbers, and methods being compared, and finally generating a title and description that will be stored in a shared state for other agents to use.
- Review Agent: Acts as an automated peer reviewer—scanning each draft for logical flow, missing or incorrect citations, adherence to target journal guidelines, and surfacing any issues (e.g., potential retractions or style violations) back to the drafting agents.
Extended Agents
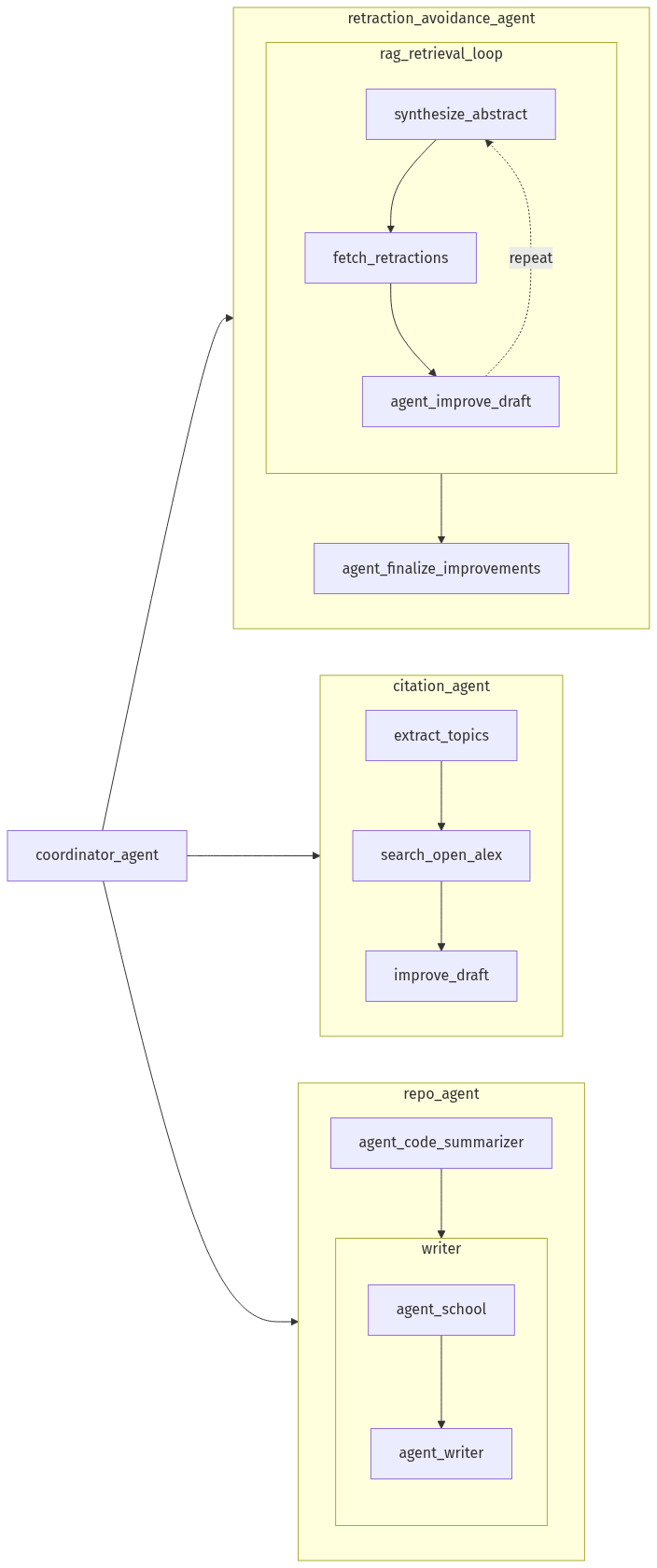
The following agents are invoked as part of extended agents which add specific capabilities we thought would be helpful for the project.
- Repository‐to‐Paper Agent: Extracts methods and implementation details directly from your code repository—parsing README, docstrings, or example scripts—to generate the “Code & Methods” and Supplementary sections, ensuring the manuscript accurately reflects the underlying software. See an example below using our Manugen-AI GitHub repository.
- Citation Agent: Manages all bibliographic work by querying OpenAlex, verifying and formatting references, and inserting in‐text citations and a properly styled reference list.
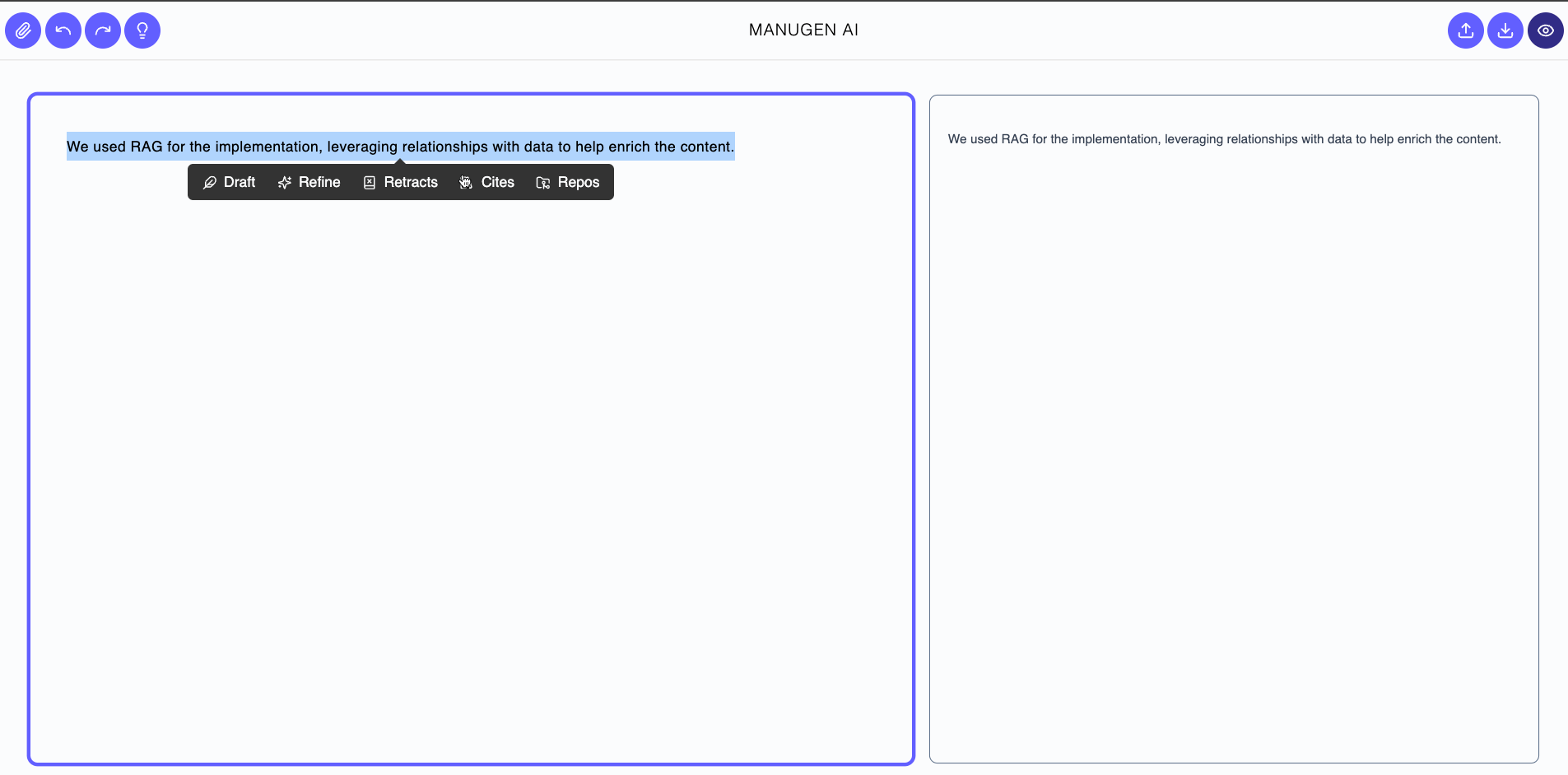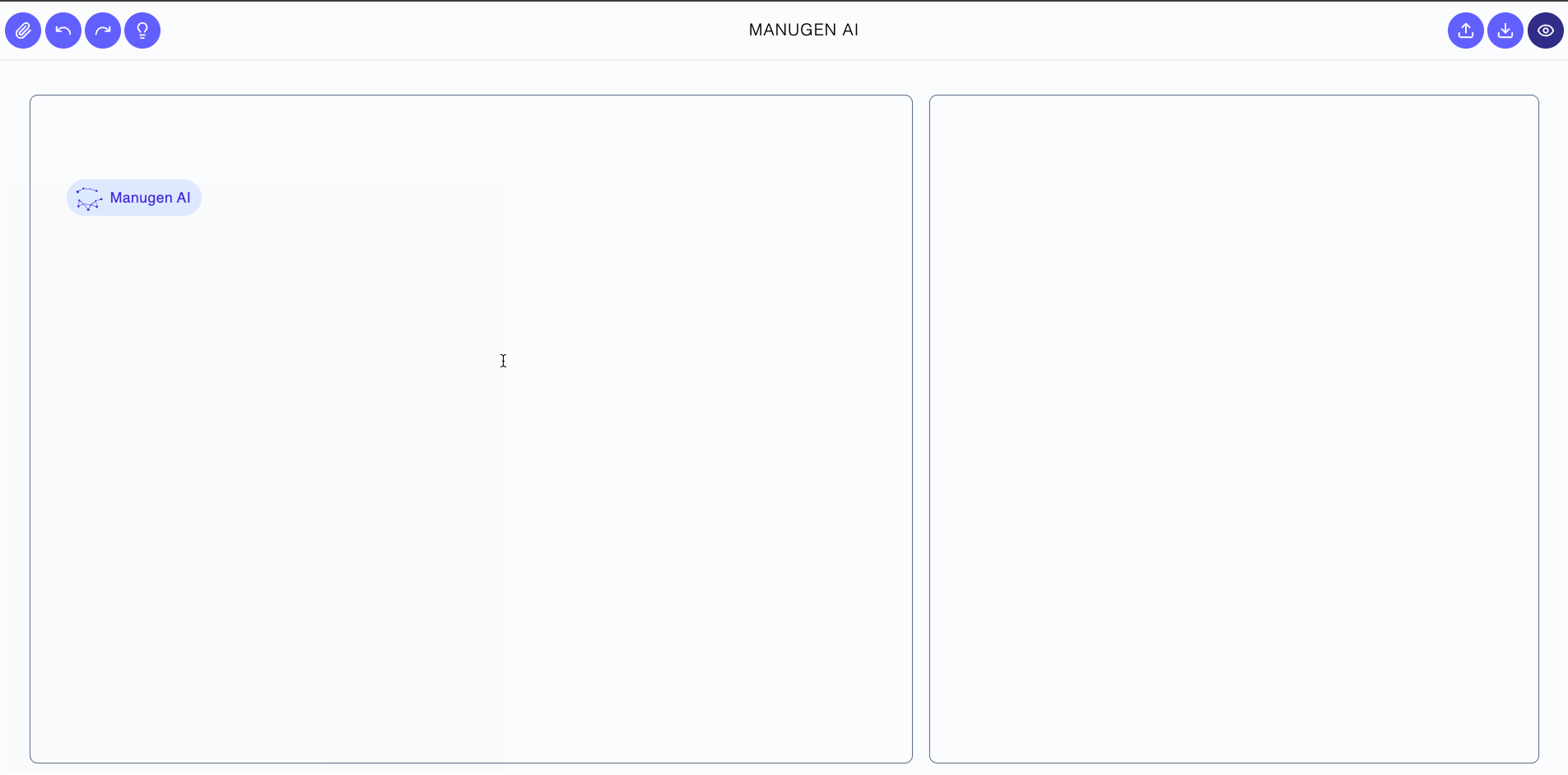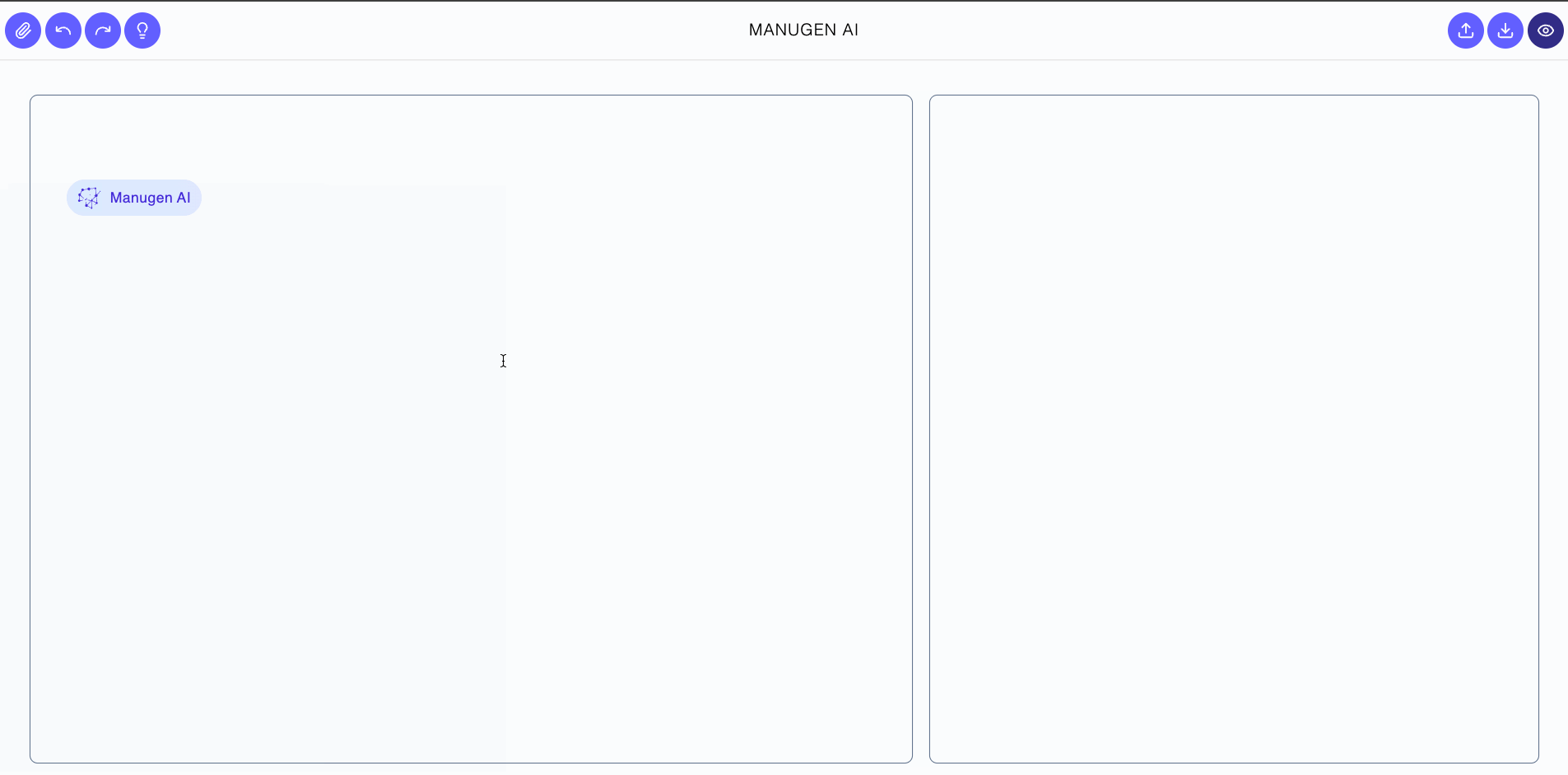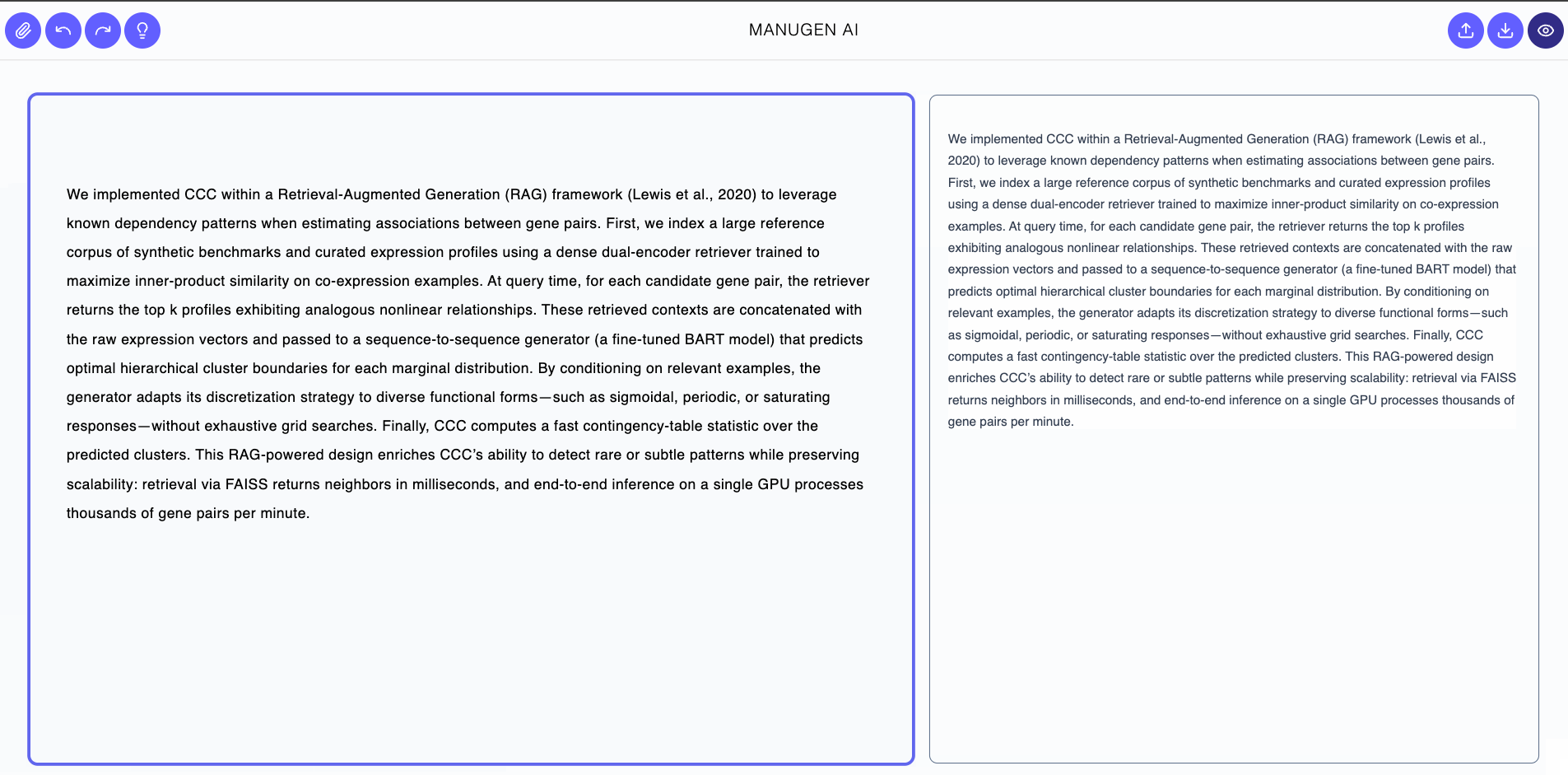
- Retraction Avoidance Agent: Uses a retrieval-augmented generation (RAG) approach and customized embeddings database based on WithdrarXiv abstracts to supply related reasons for retraction to help mitigate related challenges with the content.
Repos action demonstration
Cites action demonstration
What We Learned
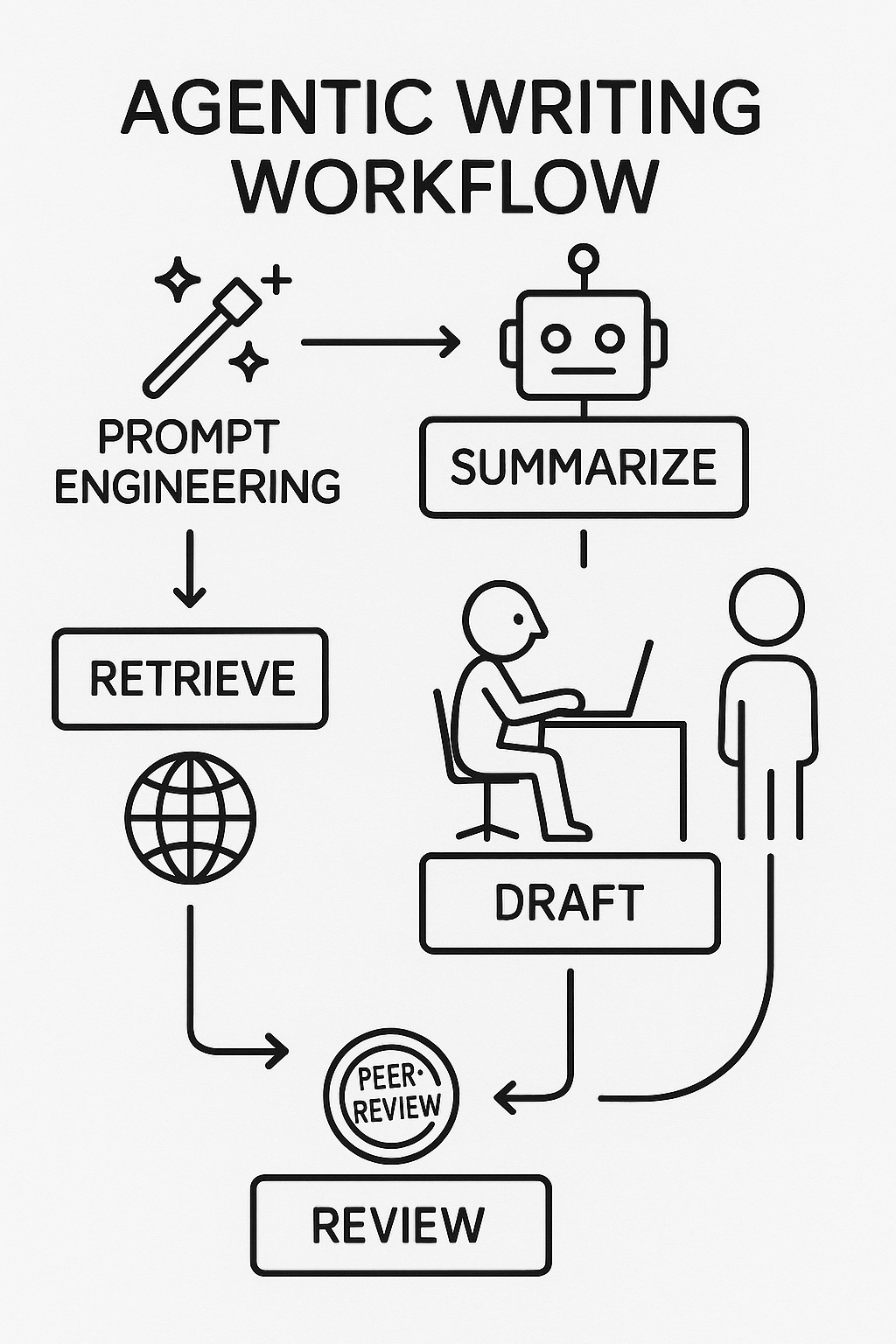
- Modular Agent Design Is Essential. By decomposing the writing process into discrete stages—literature retrieval, abstract summarization, section drafting, and peer-review simulation—agents with narrowly scoped responsibilities can be more effectively tuned and evaluated. This division of labor not only improves output quality but also makes debugging and iterating on individual components far more manageable. It also influences the required model complexity: a modular design with specialized agents focused on specific goals works well with smaller, open-source/open-weight yet powerful models that support tools, reasoning, and vision—such as Qwen3 or Gemma3—which you can run locally (e.g., via Ollama) without incurring costs or sharing sensitive content with third parties.
- Prompt Engineering Drives Quality. Small changes in how we prompted each agent had outsized effects on coherence, style, and factual accuracy. Iteratively refining prompts based on error modes (e.g., hallucinations in data-driven sections, insufficient context in methods descriptions) emerged as a critical skill.
- Integrating Retrieval Strengthens Rigor. Leveraging a dedicated retrieval agent which queries OpenAlex to ensure that our drafts were firmly grounded in existing literature, rather than relying solely on generative models. We also used WithdrarXiv through a custom-built vector embeddings database to help avoid reasons for retraction based on similar content. This hybrid retrieval-augmented approach helps reduce fabricated citations and avoids reasons for retraction to improve the manuscript’s scientific credibility.
- Automated Feedback Is Powerful, but Imperfect. Implementing a “peer-review” agent that applied heuristic and model-based checks (e.g., ensuring the presence of hypothesis statements, verifying statistical claims against source data) highlighted both the potential and current limitations of automated review. While it caught many structural issues, nuanced scientific arguments still required human oversight.
Challenges We Faced
- Maintaining Coherence Across Agents. As agents operated asynchronously, ensuring that context (e.g., variable definitions, methodological details) persisted seamlessly between stages required rigorous state-management strategies and periodic context re-injection.
- Balancing Creativity and Accuracy. Generative models can produce eloquent prose but may introduce factual inconsistencies. We mitigated this by tightly coupling drafting with retrieval, but tuning the trade-off between expressive writing and strict factuality was an ongoing challenge.
- Scaling Retrieval Latency. Querying large publication databases in real time sometimes introduced delays. Caching strategies and batched queries alleviated but did not eliminate occasional slowdowns under hackathon time constraints.
- Human-in-the-Loop Necessity. Despite our multi-agent setup, final quality assurance still relied on human review for nuanced interpretation, ethical considerations (e.g., avoiding unintended bias), and the final polish necessary for publication-ready prose.
Conclusion and Future Directions

Participating in the Devpost hackathon was an exhilarating journey that validated the power of multi-agent AI in scientific writing. In a short amount of time, we witnessed firsthand how coordinated agents could accelerate literature review, draft coherent sections, explain figures, manage citations, and perform reviews with relevant updates. The collaborative hackathon environment pushed us to solve real-world integration challenges under tight deadlines, and the results exceeded our expectations—our prototype delivered draft manuscripts far more quickly than traditional workflows.
Looking ahead, we’re excited to iterate on this foundation: refining prompt strategies to further reduce factual errors, experimenting with additional sub-agents (e.g., for data analysis or ethical bias checks), and exploring integrations with more diverse data sources to support scientific writing. By continuously benchmarking against human-authored papers and expanding our agent toolkit, we aim to uncover the full potential of Google ADK for research writing. This hackathon was just the beginning, and we’re eager to push the boundaries of what autonomous AI collaborations can achieve in scholarly publishing!